The Challenge
A large finance organization needed a faster and more reliable way to search, understand, and retrieve information from a growing collection of business documents.
Teams across multiple departments were working with reports, policies, contracts, internal documentation, and knowledge base articles stored in different repositories. Analysts often had to search manually across several systems to find the right information, which slowed down research, reporting, and decision-making.
The organization needed a document intelligence system that could answer natural language questions using its own internal knowledge sources while still allowing users to verify where each answer came from.
Our Solution
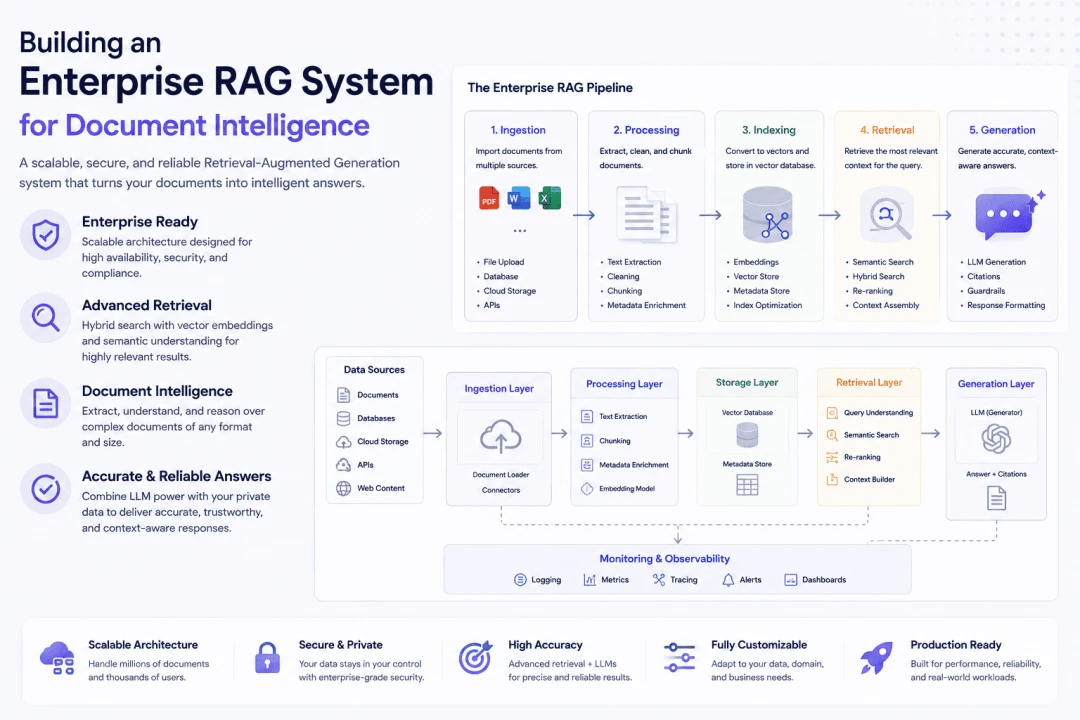
WP Stories designed and developed an enterprise RAG system that allowed users to ask questions in natural language and receive context-aware answers based on approved internal documents.
The system indexed corporate documents into a searchable knowledge layer using embeddings and vector search. When a user asked a question, the application retrieved the most relevant document chunks, passed them into a language model, and generated an answer with source references for verification.
The goal was not only to make search faster, but to make answers easier to validate, trace, and reuse across business workflows.
Key Components
Document Ingestion Pipeline
We built a document ingestion pipeline that processed multiple file formats, including PDF, DOCX, and HTML.
The pipeline extracted text, cleaned document structure, split content into optimized chunks, and prepared metadata for retrieval and citation tracking.
Vector Search Infrastructure
We implemented vector embeddings to support semantic search across the document corpus.
This allowed users to find relevant information based on meaning, not only exact keyword matches.
Vector Database Setup
We used ChromaDB to store and retrieve document embeddings efficiently.
The retrieval layer was designed to return relevant context quickly while preserving document metadata, source information, and section-level references.
Context-Aware Answer Generation
We integrated GPT-based answer generation to produce responses grounded in retrieved document context.
Instead of relying only on general model knowledge, the system generated answers from the organization’s own approved content.
Citation Tracking
We implemented citation tracking so users could verify the source of each answer.
This helped improve trust, reduce ambiguity, and support review workflows for sensitive business information.
Results
After deployment, the RAG system improved how teams accessed and reused internal knowledge.
If verified metrics are available, they can be presented as follows:If the original metrics are verified, you can use:
- 85% reduction in time spent searching for information
- 3x faster report generation
- 92% accuracy in retrieved relevant documents
- $2.4M estimated annual productivity savings
These numbers should only be published if they are backed by internal reporting, analytics, or client-approved data.
Technologies Used
- Python
- LangChain
- OpenAI API
- ChromaDB
- FastAPI
- React
- Docker
- Kubernetes
Build a RAG System for Enterprise Document Intelligence
If your organization needs to search, analyze, and retrieve answers from large document collections, WP Stories can help design and build a production-ready RAG system.
Contact WP Stories to discuss your document intelligence requirements and choose the right technical approach for your business.